 爬山虎采集器 免费软件爬山虎采集器 免费软件官方下载
爬山虎采集器 免费软件爬山虎采集器 免费软件官方下载
 Vovsoft Speech to Text Convert
Vovsoft Speech to Text Convert 发送到路过图床 免费软件
发送到路过图床 免费软件 NestingWorks 免费软件
NestingWorks 免费软件 淘宝时间同步助手(同步本机与淘
淘宝时间同步助手(同步本机与淘 E-神加密文件夹 V2006 Build 060
E-神加密文件夹 V2006 Build 060 VR Video(VR视频下载工具) v1.05
VR Video(VR视频下载工具) v1.05 Loaf(动画SVG图标编辑器) v1.1.0
Loaf(动画SVG图标编辑器) v1.1.0爬山虎采集器是最新的页面采集工具,可以帮助用户收集信息,再去针对这些内容进行一种可视化的分析,每一步都是非常的简单并且高效,能大大节省用户的时间,还在等什么呢?快来使用一下吧。
爬山虎采集器是一款新一代智能化的网页采集工具,智能分析、可视化界面,一键采集无需编程,支持自动生成采集脚本,可以采集互联网99%的网站。软件简单易学,通过智能算法+可视化界面,随心所欲,抓取自己想到的数据。只要轻松点击鼠标,就能采集网页上的数据。
软件特色
1.独创高速内核
自研的浏览器内核,速度飞快,远超对手
2.智能识别
对于网页中的列表、表单结构(多选框下拉列表等)能够智能识别
3.广告屏蔽
定制的广告屏蔽模块,兼容AdblockPlus语法,可添加自定义规则
4.多种数据导出
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等
5.一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
6.快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
7.适用各种网站
能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
软件功能
1、从任何地方的任何数据的恢复
2、支持超过550种数据格式,包括几乎所有的图像文件、多媒体文件、电子邮件、档案等。
3、支持所有设备的完整数据恢复NTFS,FAT16,FAT32,HFS+,APF,等。
4、先进的算法支持
5、更快的扫描速度由一个内置强大的数据分析引擎驱动。
软件特点
1、简单易用的向导驱动界面;
2、PC 或 Mac 上工作完全相同;
3、能够扫描本地计算机中的所有卷并生成丢失和已删除文件的目录树;
4、搜索匹配文件名条件的丢失和已删除文件;
5、快速扫描引擎允许快速构建文件列表;
6、简单明了的文件管理器和典型的保存文件对话框;
7、安全数据恢复:EasyRecovery不会对其正在扫描的驱动器进行写入操作;
8、可以将数据保存到任何驱动器,包括网络驱动器、可移动媒体等等;
9、支持 Windows NTFS 的压缩和加密文件;
10、电子邮件恢复允许用户查看选定的电子邮件数据库。将现有的和已删除的电子邮件都显示出来,可以用于打印或保存到硬盘。
用户下载了爬山虎采集器之后,可能对于这类软件的基本操作不是很了解,所以往往就会出现使用困难的情况,为了帮助用户可以更好的知晓爬山虎采集器的使用方法,下面就来讲解一下采集任务的新建方法,有需要的用户快来了解一下吧。
创建第一个采集任务
首先,打开爬山虎采集器,点击主界面的新建任务按钮
第一步、选择起始网址
当你想要采集一个网站数据时,首先需要找到一个展示数据列表的地址。这一步,至关重要,起始网址决定了你采集的数据数量和类型。
以大众点评为例,我们想要抓取当前城市的美食类的商家信息,包括店名、地址、评分等等信息。
通过浏览网站,我们找到所有美食类的商家列表地址
然后在爬山虎采集器V2中新建任务->第一步->输入网页地址
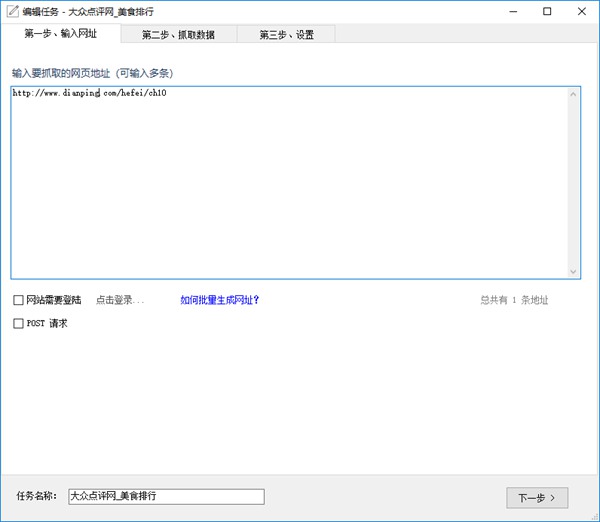
然后点击下一步。
第二步、抓取数据
进入到第二步后,爬山虎采集器会智能分析网页,并且从中提取出列表数据。如下图:
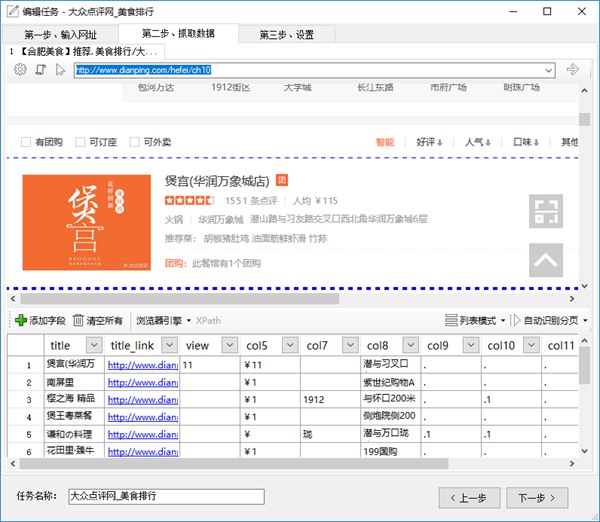
这时,我们对已经分析出的数据进行整理修改,比如删掉无用的字段。
点击列的下拉按钮,选择删除字段。
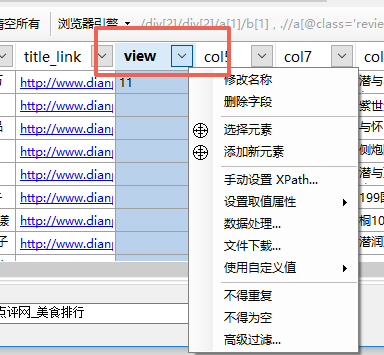
当然还是其他操作,比如修改名称,数据处理等等。这些我们将在后面的文档中介绍。
在整理修改字段后,我们来采集处理分页。
选择分页设置->自动识别分页,程序将会自动定位下一页元素。
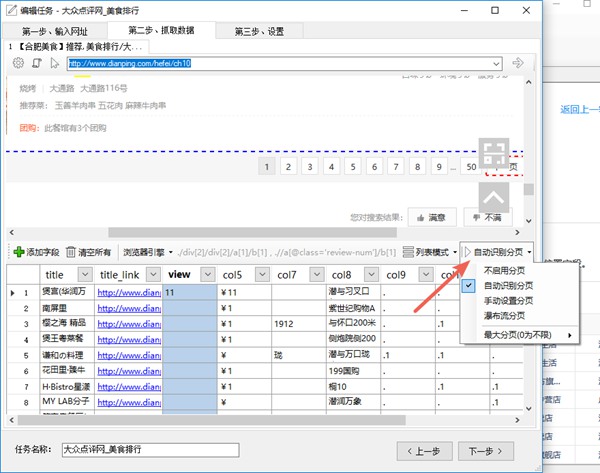
完成之后,点击下一步。
第三步、设置
这里包括对浏览器的配置,比如禁用图片、禁用JS、禁用Flash、拦截广告等等操作。可以通过这些配置提高浏览器的加载速度。
计划任务的配置,通过计划任务,可以设置任务定时自动运行。
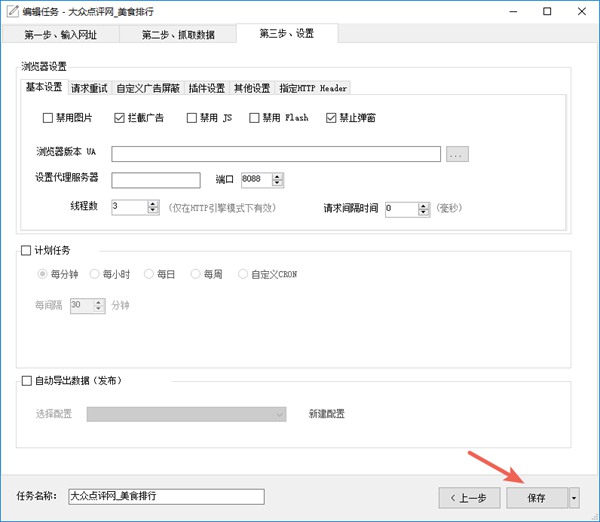
点击完成,保存任务。
完成,运行任务
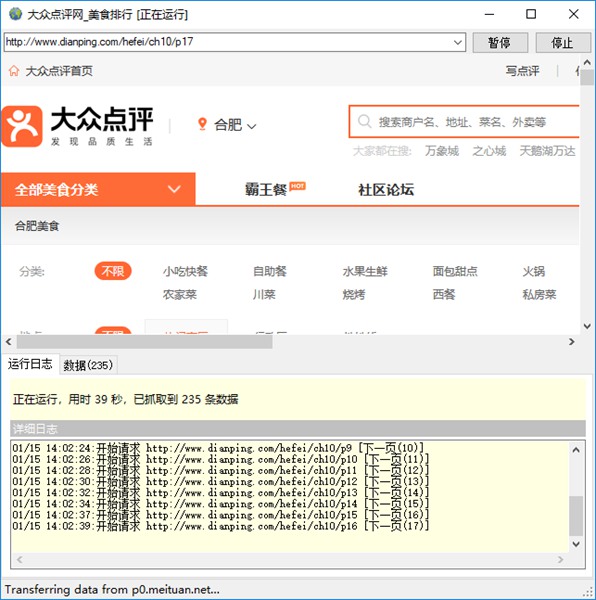
任务创建完成之后,我们选择刚刚新建的任务,点击主界面工具栏开始按钮。
任务运行窗口,任务运行日志,记录详细采集日志信息。
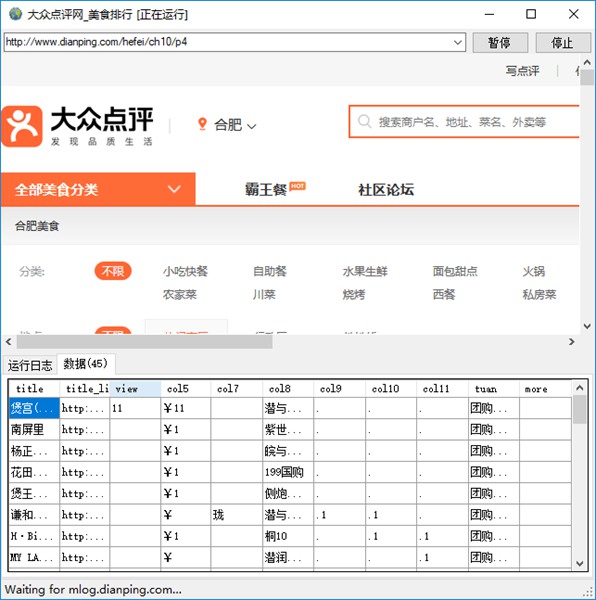
已采集数据窗口,实时显示已采集的数据
对于用户来说,单单只是上面的采集基本信息是远远不够的,因为图片对于用户来说也是非常重要的一个方面,为了更好的帮助到大家快速的知晓图片采集的基本步骤,实现图片快速保存的操作,下面就来分享一下相关的采集方法,来看看吧。
1.点击添加字段。
2.鼠标点击网页中的图片,程序自动获取图片地址。(已有字段,选择重新选择元素,然后点击图片)
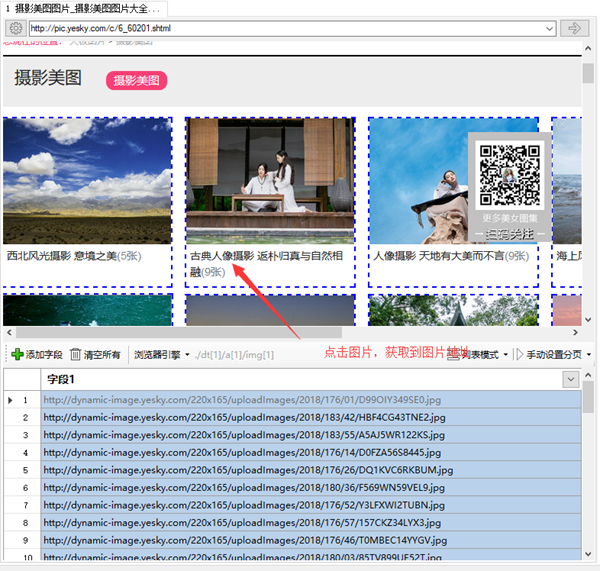
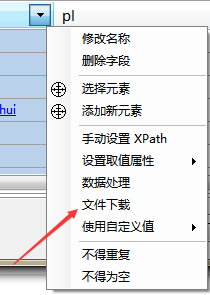
3.选择要下载的字段,点击菜单按钮,选择文件下载菜单。
4.设置文件名和图片的保存路径。
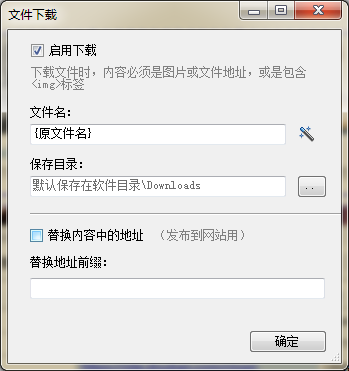
5.完成。
怎么自定义广告屏蔽有的用户在使用爬山虎采集器的时候,就会发现自己想要去采集的页面会有非常多的广告,这些东西都是没有用处的,会干扰正常的采集操作,增加不必要的存储空间,所以自定义广告屏蔽是非常重要的,下面就来分享一下相关屏蔽的方法,快来看看吧。
在爬山虎采集器中,可以通过自定义广告屏蔽,来加快采集速度。
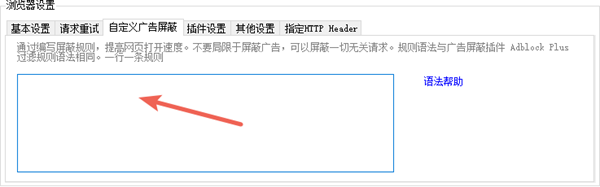
具体语法参考 AdBlock Plus 过滤规则 ,规则为一行一个。
最常用的就是使用通配符,在指定字符前后加星号 *
技巧
一般我们在采集时,注意观察运行日志,如果出现了如下提示:
页面加载超过 30 秒限制. 超时请求: Transferring data from ih1.redbubble.net…
我们可以添加规则:*ih1.redbubble.net* ,过滤掉所有包含 ih1.redbubble.net 的请求,这种请求一般是外站图片、或者js请求。
注意:不要屏蔽你采集的网站主域名,比如你要采集 https://www.baidu.com/s?wd=x ,却加上规则 *www.baidu.com*,这样的话,可能就采集不到数据。
常见问题
问:如何过滤列表中的前N个数据?
1.有时我们需要对采集到的列表进行过滤,比如过滤掉第一组数据(在采集表格时,过滤掉表格列名)
2.点击列表模式菜单中的,设置列表xpath
问:如何抓包获取Cookie,并且手动设置?
1.首先,使用谷歌浏览器打开要采集的网站,并且登陆。
2.然后按下 F12,会出现开发者工具,选择 Network
3.然后按下F5,刷新下页面, 选择其中一个请求。
4.复制完成后,在爬山虎采集器中,编辑任务,进入第三步,指定HTTP Header。
更新日志
新增数据查看- 预览、编辑完整数据
新增数据查看- 执行 sql 功能
数据处理,新增 自动补全相对URL功能
对单个脚本命令 可设置所有分页执行(右击命令行
修改文本框高亮
修复innerText包含style、script问题
修复其他等问题
同类软件精选
用户最爱